


Data Science Team Lead в Яндекс
Дмитрий Сафонов


Diffusion Models для генерации табличных данных
Диффузионные модели постепенно находят применение в работе с табличными данными. На первый взгляд идея кажется странной: зачем «тащить» подход из компьютерного зрения в таблицы, если есть GAN’ы и классический SMOTE?
На практике оказывается, что диффузия решает ряд задач лучше альтернатив: точнее воспроизводит сложные зависимости между признаками и позволяет контролировать процесс генерации. Сегодня этот подход используется для аугментации данных о редких событиях в финтехе, медицине и ритейле.
В статье разберём, что это за метод и как его применять.
На практике оказывается, что диффузия решает ряд задач лучше альтернатив: точнее воспроизводит сложные зависимости между признаками и позволяет контролировать процесс генерации. Сегодня этот подход используется для аугментации данных о редких событиях в финтехе, медицине и ритейле.
В статье разберём, что это за метод и как его применять.

1. Зачем генерировать табличные данные
«Зачем выдумывать данные, если можно собрать настоящие?» — первое, что спрашивают, когда речь заходит о синтетике. На практике ситуаций, когда генерация действительно нужна, достаточно много.
- Самая частая — дисбаланс классовВ задачах fraud detection мошеннических транзакций обычно доли процента от всего датасета. Классические методы вроде SMOTE создают новые примеры путём интерполяции между существующими, что даёт «усреднённые» точки, не отражающие реальное разнообразие данных. Диффузионные модели учатся воспроизводить всё распределение, включая сложные зависимости между признаками — например, что для определённого типа мошенничества характерны одновременно ночные транзакции, круглые суммы и новые устройства.
- Второй большой сценарий — приватность данныхРеальные данные часто нельзя передать — персональная информация, регуляторные ограничения. Синтетические датасеты статистически неотличимы от реальных, но не содержат информации о конкретных клиентах.
- Есть и более простые случаи: аугментация маленьких датасетов, когда 500 примеров недостаточно для обучения, или тестирование пайплайнов на данных, которых ещё не существует.
2. Как работают диффузионные модели
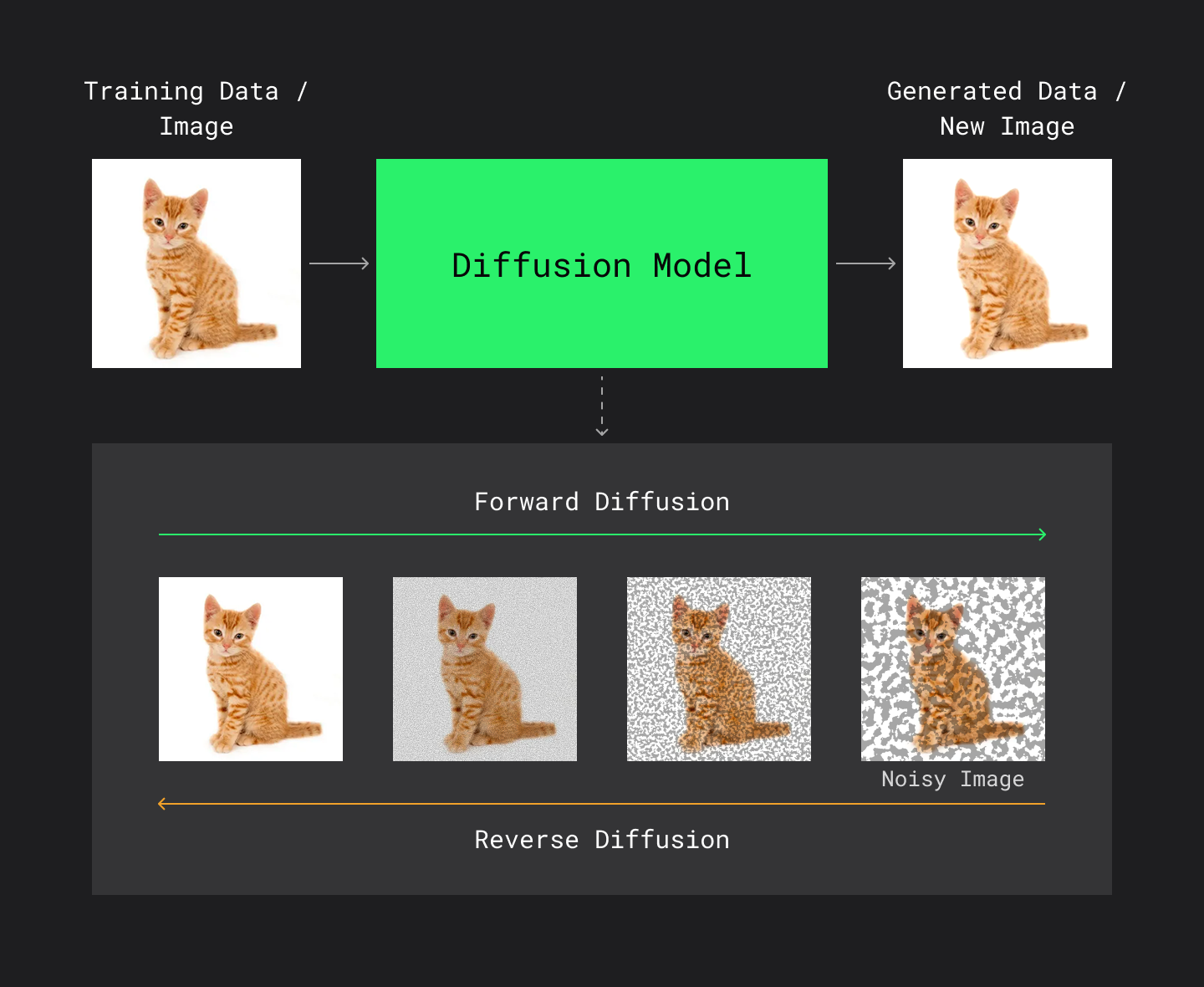
Интуиция в двух абзацах
Forward process: берём реальную строку таблицы и постепенно добавляем шум. За T шагов данные превращаются в чистый гауссовский шум.
Reverse process: нейросеть учится предсказывать, какой шум был добавлен на каждом шаге. При генерации берём случайный шум и пошагово «очищаем» его, получая реалистичную строку.
Ключевое отличие от GAN: нет adversarial-обучения, нет mode collapse и стабильный training.
3. Почему диффузия, а не GAN или VAE
Рассмотрим ключевые отличия VAE, GAN и диффузионных моделей именно в контексте табличных данных, опираясь на эксперименты.
Критерий
VAE (TVAE)
GAN (CTABGAN+)
Диффузия (TabDDPM и др.)
Качество распределений фич
Нормальное, но сглаженное repository.tudelft+1
Может быть очень высоким, но с риском mode collapse
На реальных датасетах обычно лучшая близость к real dist.research.yandex+1
Utility в down‑stream задачах
Часто ок, иногда уступает GAN/дифф
Нестабильное: от отличного до провального
Средний ранг лучший среди TVAE/CTABGAN+/SMOTE в TabDDPM
Чувствительность к гетерогенности (num+cat, high‑cardinality)
Средняя
Высокая, нужны хитрые трюки с кодированием
Особенно хорошо ведёт себя на таких признаках
Стабильность обучения
Высокая
Низкая, тюнинг сложный
Выше, чем у GAN, но обучение и инференс тяжелее
Скорость генерации
Быстрая
Очень быстрая
Существенно медленнее (много шагов диффузии)
Интерпретируемость
Хорошая, есть плотность и LL
Латент плохо интерпретируем, LL нет
Можно оценивать плотность, но латент не так удобен, как у VAE
Классические VAE‑подходы (например, TVAE) обеспечивают стабильное обучение и интерпретируемое латентное представление, но часто переупрощают реальные распределения признаков.
GAN‑модели (вроде CTABGAN+) способны лучше подстраиваться под сложные структуры, однако страдают от нестабильного обучения и mode collapse, из‑за чего покрытие пространства данных оказывается ограниченным.
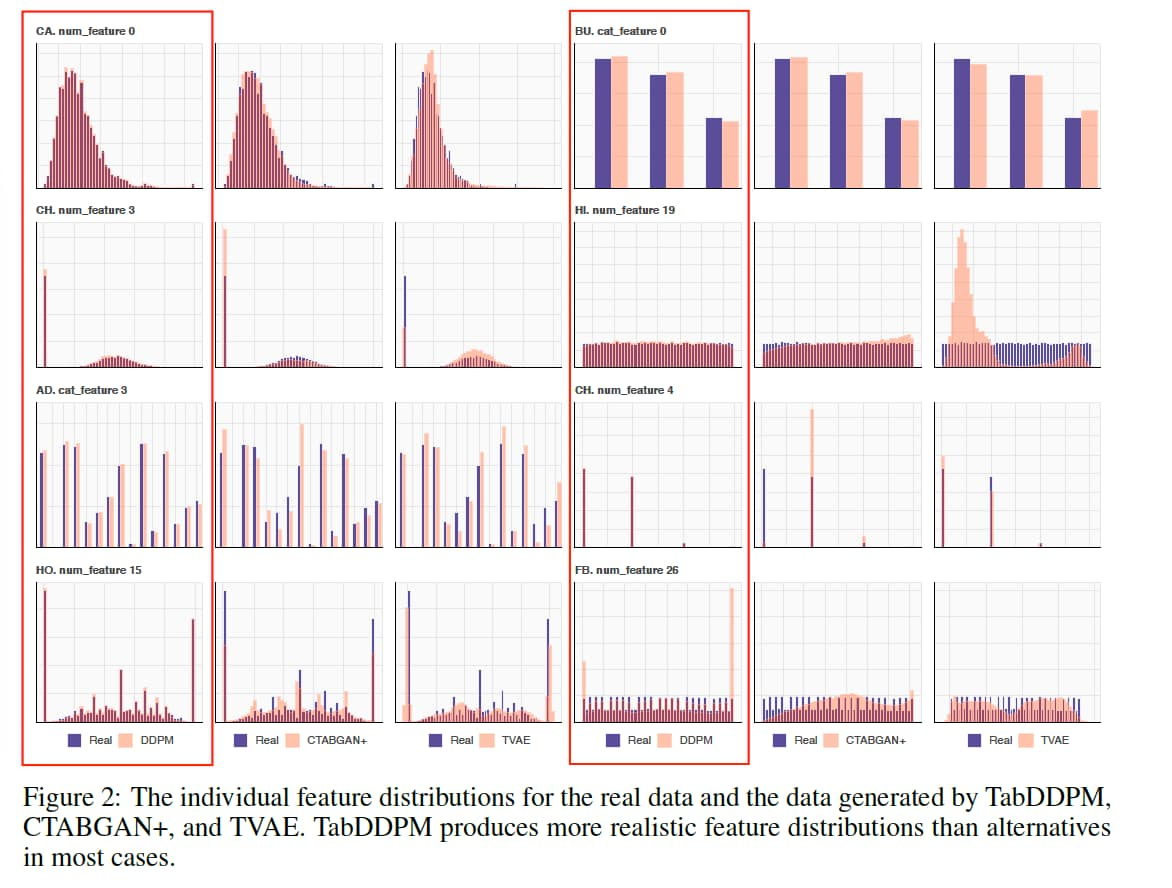
Диффузионные методы, такие как TabDDPM, демонстрируют более реалистичные распределения как числовых, так и категориальных признаков и в среднем дают лучшую utility‑метрику в down‑stream задачах по сравнению с VAE и GAN, хотя требуют существенно больших вычислительных ресурсов и времени генерации.
GAN‑модели (вроде CTABGAN+) способны лучше подстраиваться под сложные структуры, однако страдают от нестабильного обучения и mode collapse, из‑за чего покрытие пространства данных оказывается ограниченным.
Диффузионные методы, такие как TabDDPM, демонстрируют более реалистичные распределения как числовых, так и категориальных признаков и в среднем дают лучшую utility‑метрику в down‑stream задачах по сравнению с VAE и GAN, хотя требуют существенно больших вычислительных ресурсов и времени генерации.
4. Инструменты: что выбрать
Среди наиболее известных решений — TabDDPM и TabDiff. Обе модели основаны на диффузионном процессе, но различаются архитектурой, обработкой категориальных признаков и гибкостью настройки.
TabDDPM:
- основан на классическом DDPM (Denoising Diffusion Probabilistic Model)
- использует MLP-архитектуру
- требует явного кодирования категориальных признаков (обычно one-hot)
- отдельно обрабатывает числовые и категориальные данные
TabDiff:
- более современный вариант диффузионной модели
- часто использует эмбеддинги категориальных признаков вместо one-hot
- лучше масштабируется на смешанные типы данных
- более гибкая схема шумового расписания
В TabDDPM требуется заранее подготовленный тензор признаков:
import torch
from tabddpm import TabDDPM
X_num = torch.tensor(df\[num_cols\].values, dtype=torch.float32)
X_cat = torch.tensor(encoded_cat, dtype=torch.float32)
X = torch.cat(\[X_num, X_cat\], dim=1)
model = TabDDPM(
input_dim=X.shape\[1\],
hidden_dim=512,
num_timesteps=1000
)
model.fit(X, epochs=200, batch_size=256)
synthetic_data = model.sample(1000)В TabDiff предусмотрена нативная поддержка категориальных признаков через эмбеддинги:
import torch
from tabdiff import TabDiff
model = TabDiff(
num_numeric=len(num_cols),
cat_cardinalities=[df[c].nunique() for c in cat_cols],
embedding_dim=32,
hidden_dim=512,
num_timesteps=1000
)
X_num = torch.tensor(df[num_cols].values, dtype=torch.float32)
X_cat = torch.tensor(df[cat_cols].values, dtype=torch.long)
model.fit(
numeric_data=X_num,
categorical_data=X_cat,
epochs=200,
batch_size=256
)
synthetic_num, synthetic_cat = model.sample(1000)Когда выбирать?
Если датасет небольшой и категориальных признаков немного — TabDDPM будет простым и понятным вариантом.
Если много категориальных признаков с высокой кардинальностью — TabDiff обычно показывает лучшую производительность и устойчивость.
5. Заключение
Когда использовать Diffusion Models:
- Критичны корреляции между фичами
- Нужна conditional generation
- Датасет средний (1K–1M строк)
- Есть время на обучение
Когда НЕ использовать:
- Нужна быстрая генерация в реальном времени
- Очень маленький датасет (<500 строк)
- Данные с очень высокой размерностью (>100 фич) без доработок
Важно помнить, что успех зависит не только от архитектуры, но и от корректной предобработки данных, выбора шумового расписания, числа шагов диффузии и стратегии сэмплирования.
Поэтому лучший подход — рассматривать диффузионные модели как гибкий инструмент и тестировать их в рамках конкретного сценария.
Поэтому лучший подход — рассматривать диффузионные модели как гибкий инструмент и тестировать их в рамках конкретного сценария.
бесплатные уроки по data science