





Apache Kafka за 5 минут: зачем она нужна?

Автор — Андрей Серебрянский
Ведущий разработчик из Яндекса
Современные IT-системы генерируют миллионы событий в секунду. Без надёжного механизма обмена сообщениями сервисы сталкиваются с перегрузкой, каскадными отказами и потерей данных. Классические очереди или прямые REST/gRPC вызовы сложно масштабировать на очень большие объемы.
Kafka решает эти проблемы: обеспечивает безопасный обмен данными между сервисами, масштабируемость потоков и возможность повторного чтения сообщений.
В этой статье мы подробно рассмотрим, где и как используется Apache Kafka, какие проблемы она решает, ключевые концепции (топики, партиции, брокеры, retention) и практическую пользу для масштабных систем.
Kafka решает эти проблемы: обеспечивает безопасный обмен данными между сервисами, масштабируемость потоков и возможность повторного чтения сообщений.
В этой статье мы подробно рассмотрим, где и как используется Apache Kafka, какие проблемы она решает, ключевые концепции (топики, партиции, брокеры, retention) и практическую пользу для масштабных систем.

1. Где и зачем используется Kafka на практике?
Kafka используется практически в каждой крупной IT-компании для самых разных целей:
- Обмен сообщениями между микросервисамиВ распределённых системах сервисы часто обмениваются событиями и данными в реальном времени. Apache Kafka позволяет сервисам писать сообщения в топики и читать их независимо друг от друга, без риска перегрузки или каскадных отказов.
На практике это позволяет, например, сервису оплаты безопасно уведомлять сервис доставки о новых заказах. - Сбор событий с мобильных устройствКогда пользователи кликают, переходят между экранами или совершают действия в приложении, эти события нужно фиксировать. Обычно они сначала отправляются в Kafka, где агрегируются и обрабатываются в реальном времени
- Сбор логов, метрик и трейсов приложенийВсе события и ошибки приложений можно собирать в Kafka, прежде чем отправлять в системы мониторинга.
Например, логи микросервисов, метрики производительности и трассировки запросов часто сначала проходят через Kafka, чтобы их можно было безопасно буферизовать и агрегировать. Только после этого они поступают в Prometheus или другие хранилища для визуализации и анализа. - Поставка данных в дата-платформу организацииВ крупных компаниях данные поступают из разных источников: базы данных, другие брокеры сообщений, сторонние сервисы. Kafka служит центральной шиной, где все эти данные аккумулируются и синхронизируются с дата-платформой.
На практике это позволяет строить единое место хранения для аналитики, машинного обучения и отчетности, при этом не перегружая исходные источники данных.
Kafka используется по всему миру и стала стандартом для обработки больших потоков данных. Некоторые компании используют её с невероятной интенсивностью.
Например, Kafka появилась в LinkedIn в 2011 году и с тех пор компания значительно увеличила масштабы её использования. Сейчас через Apache Kafka проходит порядка 200 гигабайт данных в секунду. Чтобы справиться с такой нагрузкой, в LinkedIn задействованы около 10 тысяч брокеров — это серверы, которые входят в кластер Kafka и отвечают за хранение и обработку сообщений. В Kafka один такой сервер называется брокером.
В Netflix потоки данных тоже колоссальные. Каждое ваше действие — открытие видео, нажатие паузы, смена качества — фиксируется и сохраняется. Система генерирует порядка 230 миллионов событий в секунду, которые нужно надёжно обработать и сохранить.
В Netflix потоки данных тоже колоссальные. Каждое ваше действие — открытие видео, нажатие паузы, смена качества — фиксируется и сохраняется. Система генерирует порядка 230 миллионов событий в секунду, которые нужно надёжно обработать и сохранить.
2. Как появилась Kafka
Начнем с того, как всё выглядело до появления брокеров сообщений. Раньше сервисы напрямую вызывали друг друга через API.
На практике это создаёт несколько проблем:
Backpressure — буквально «давление» на сервис. Если один сервис отправляет слишком много запросов другому, второй сервис не успевает их обработать и может полностью отказать.
На практике это создаёт несколько проблем:
Backpressure — буквально «давление» на сервис. Если один сервис отправляет слишком много запросов другому, второй сервис не успевает их обработать и может полностью отказать.

Каскадные отказы — когда один сервис падает, от него зависят другие, и ошибки начинают распространяться дальше. В итоге пользователи получают сбои, а система постепенно выходит из строя.

Чтобы решать эти проблемы, появились очереди сообщений (message queues).

На практике это работает так:
- писатель (например, сервис регистрации событий) может быстро отправлять сообщения в очередь — она надёжно их сохраняет;
- читатель (например, аналитический сервис или база данных) получает сообщения в своём собственном темпе, без давления со стороны писателя.

Таким образом, читатель становится полностью независимым от писателя. Даже если один сервис откажет, остальные продолжают работать, потому что они не взаимодействуют напрямую — они просто пишут и читают сообщения через брокер сообщений, который выступает надежным буфером между ними.
3. Ограничения классических очередей
С ростом количества данных и числа брокеров стали проявляться новые проблемы классических очередей сообщений:
Очередь как узкое место. Одна очередь находится на одном сервере и раздувается до огромного размера, она может полностью занять ресурсы процессора и памяти. В итоге остальные очереди на этом же сервере не получают ресурсы и начинают функционировать с перебоями.
Очередь как узкое место. Одна очередь находится на одном сервере и раздувается до огромного размера, она может полностью занять ресурсы процессора и памяти. В итоге остальные очереди на этом же сервере не получают ресурсы и начинают функционировать с перебоями.


Сложности с повторной обработкой данных. После того как сообщение было прочитано и подтверждено читателем, оно удаляется из очереди. Если при обработке произошла ошибка, перечитать данные становится сложно. Писатель может попытаться отправить их повторно, но это не всегда возможно и может нарушить порядок сообщений.

Отсутствие прозрачности. Часто сложно понять, какие именно сообщения были в очереди в момент ошибки. Можно настроить хранение логов, но это дополнительная работа, и далеко не все системы делают это по умолчанию.
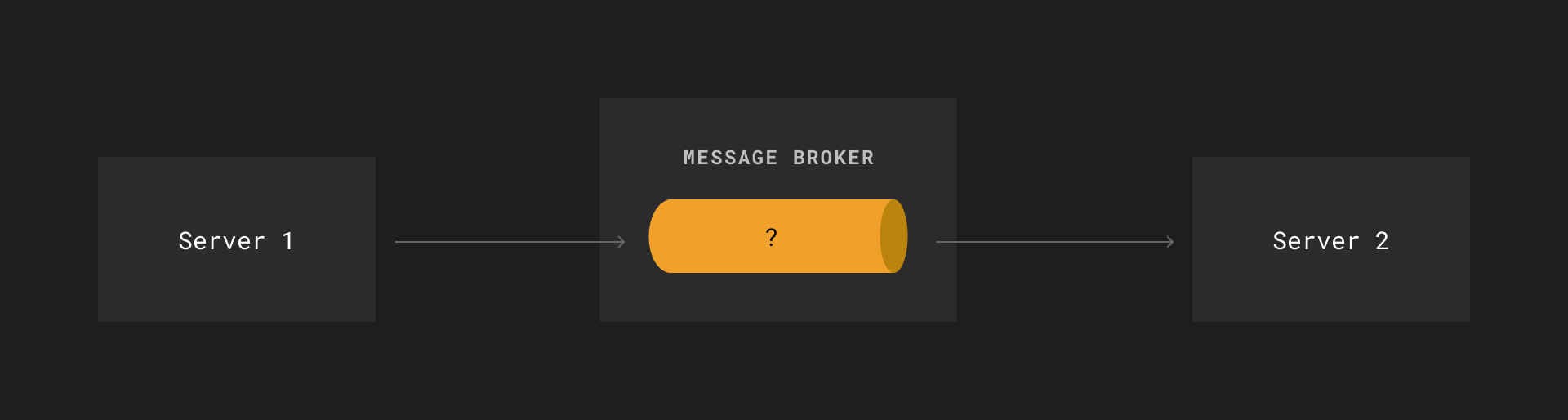
В совокупности эти ограничения показывают, что классические очереди не всегда справляются с высокими нагрузками и сложными сценариями обработки данных.
4. Как Kafka решает эти проблемы?
Большая монолитная очередь могла занимать значительную часть ресурсов сервера, тем самым мешая работе других, менее нагруженных очередей, а также сама могла не справляться с поступающим объемом данных.
Решение проблемы backpressure
В архитектуре Kafka вводится новое базовое понятие — топик.
Топик представляет собой набор сообщений, объединённых общей тематикой. Например, в один топик могут попадать все сообщения о банковских транзакциях, а сообщения, связанные с оформлением кредита, будут попадать в другой топик, так как относятся к другой предметной области.
Каждый топик состоит из партиций (partitions), которые распределяются по кластеру.
Топик представляет собой набор сообщений, объединённых общей тематикой. Например, в один топик могут попадать все сообщения о банковских транзакциях, а сообщения, связанные с оформлением кредита, будут попадать в другой топик, так как относятся к другой предметной области.
Каждый топик состоит из партиций (partitions), которые распределяются по кластеру.

Топик состоит из партиций, которые распределены по брокерам, а запись равномерно распределена
Если представить систему на схеме, где есть несколько брокеров, то один топик с именем My-Topic может быть разделен на три партиции, и каждая из этих партиций размещается на отдельном сервере, то есть на отдельном брокере.
Продюсеры, которые записывают сообщения в этот топик, распределяют нагрузку между несколькими серверами, что позволяет избежать перегрузки одного узла.
Если нагрузка на систему растёт, например, бизнес начинает генерировать значительно больше сообщений, мы можем масштабировать систему горизонтально: добавлять новые серверы Kafka, то есть новые брокеры, и увеличивать количество партиций, чтобы распределять поток сообщений ещё более равномерно.
Продюсеры, которые записывают сообщения в этот топик, распределяют нагрузку между несколькими серверами, что позволяет избежать перегрузки одного узла.
Если нагрузка на систему растёт, например, бизнес начинает генерировать значительно больше сообщений, мы можем масштабировать систему горизонтально: добавлять новые серверы Kafka, то есть новые брокеры, и увеличивать количество партиций, чтобы распределять поток сообщений ещё более равномерно.
Решение проблемы повторного чтения сообщений
В классических очередях после обработки сообщение удаляется, и если в коде допущена ошибка, повторно обработать это сообщение уже невозможно.
В Kafka ситуация иная: данные можно читать многократно. Сообщения не удаляются сразу после прочтения и остаются доступными для повторного чтения.
Когда же тогда данные удаляются из Kafka? По умолчанию хранение ограничено семью днями, однако на практике удаление данных определяется политикой retention.
Срок хранения задаётся параметром retention.ms, который определяет время хранения сообщений. Также существует параметр retention.bytes, который ограничивает объём данных в топике, и при превышении этого лимита старые сообщения начинают удаляться.
Важно понимать, что сообщения доступны для чтения в течение всего периода retention. Независимо от того, задано ограничение по времени или по объёму, данные остаются в Kafka до момента истечения настроенного срока хранения, и в течение этого времени их можно читать любое количество раз.
В Kafka ситуация иная: данные можно читать многократно. Сообщения не удаляются сразу после прочтения и остаются доступными для повторного чтения.
Когда же тогда данные удаляются из Kafka? По умолчанию хранение ограничено семью днями, однако на практике удаление данных определяется политикой retention.
Срок хранения задаётся параметром retention.ms, который определяет время хранения сообщений. Также существует параметр retention.bytes, который ограничивает объём данных в топике, и при превышении этого лимита старые сообщения начинают удаляться.
Важно понимать, что сообщения доступны для чтения в течение всего периода retention. Независимо от того, задано ограничение по времени или по объёму, данные остаются в Kafka до момента истечения настроенного срока хранения, и в течение этого времени их можно читать любое количество раз.
5. Заключение
Kafka стала ключевым инструментом для работы с потоками данных в современных IT-компаниях. Она используется практически повсеместно — от обмена сообщениями между микросервисами и сбора событий с мобильных приложений до агрегации логов, метрик и централизованной доставки данных в дата-платформы.
История Kafka показывает, как технология развивалась, чтобы решать реальные практические проблемы:
В совокупности преимущества Kafka состоят в том, что она решает ограничения классических очередей сообщений, обеспечивает отказоустойчивость и гибкость обработки потоков данных, делая систему более надежной и масштабируемой.
История Kafka показывает, как технология развивалась, чтобы решать реальные практические проблемы:
- контроль нагрузки и backpressure — Kafka позволяет распределять нагрузку между партициями и брокерами, так что ни один сервер не перегружается, а писатели и читатели работают независимо;
- повторное перечитывание сообщений — сообщения можно читать сколько угодно раз в течение периода хранения (retention), что облегчает исправление ошибок и повторную обработку данных;
В совокупности преимущества Kafka состоят в том, что она решает ограничения классических очередей сообщений, обеспечивает отказоустойчивость и гибкость обработки потоков данных, делая систему более надежной и масштабируемой.
Другие статьи
В реальных проектах Apache Kafka часто используется для отправки уведомлений, логов и событий аналитики. Один сервис формирует сообщение, другой принимает его и запускает дальнейший этап обработки. С ее помощью сервисы могут обмениваться информацией независимо друг от друга, что упрощает масштабирование системы и снижает количество межсервисных зависимостей.
В простом случае брокер сообщений позволяет сервисам передавать данные без прямого взаимодействия. Один сервис публикует событие, а остальные получают его тогда, когда это необходимо. Такой механизм хорошо подходит для микросервисной архитектуры и помогает снизить связанность между компонентами.
Несмотря на тесную связь с экосистемой java, Apache Kafka давно вышла за ее пределы. Благодаря различным клиентам и api платформа легко интегрируется в существующие проекты. При большом количестве запросов Apache Kafka помогает распределять нагрузку между несколькими узлами и уменьшать задержки при выполнении отдельных операции.
В реальных проектах Apache Kafka часто используется для отправки уведомлений, логов и событий аналитики. Один сервис формирует сообщение, другой принимает его и запускает дальнейший этап обработки. Такой подход хорошо работает в распределенных системах и упрощает масштабирование.
Большое значение имеет и настройка кластера. Правильно выбранная политика хранения и фактор репликации помогают обеспечить надежность системы и избежать потери данных. При необходимости сообщения можно повторно прочитать, а устаревшие записи удаляются автоматически.
Для опытных разработчиков Apache Kafka интересна не только в качестве брокера сообщений, ведь это еще и инструмент построения событийной архитектуры. Apache Kafka позволяет организовать распределение потоков данных и более эффективно использовать ресурсы системы. При росте нагрузки с Apache Kafka можно автоматически добавлять новые узлы, сохраняя и поддерживая стабильную работу сервисов.
В простом случае брокер сообщений позволяет сервисам передавать данные без прямого взаимодействия. Один сервис публикует событие, а остальные получают его тогда, когда это необходимо. Такой механизм хорошо подходит для микросервисной архитектуры и помогает снизить связанность между компонентами.
Несмотря на тесную связь с экосистемой java, Apache Kafka давно вышла за ее пределы. Благодаря различным клиентам и api платформа легко интегрируется в существующие проекты. При большом количестве запросов Apache Kafka помогает распределять нагрузку между несколькими узлами и уменьшать задержки при выполнении отдельных операции.
В реальных проектах Apache Kafka часто используется для отправки уведомлений, логов и событий аналитики. Один сервис формирует сообщение, другой принимает его и запускает дальнейший этап обработки. Такой подход хорошо работает в распределенных системах и упрощает масштабирование.
Большое значение имеет и настройка кластера. Правильно выбранная политика хранения и фактор репликации помогают обеспечить надежность системы и избежать потери данных. При необходимости сообщения можно повторно прочитать, а устаревшие записи удаляются автоматически.
Для опытных разработчиков Apache Kafka интересна не только в качестве брокера сообщений, ведь это еще и инструмент построения событийной архитектуры. Apache Kafka позволяет организовать распределение потоков данных и более эффективно использовать ресурсы системы. При росте нагрузки с Apache Kafka можно автоматически добавлять новые узлы, сохраняя и поддерживая стабильную работу сервисов.