
Какие задачи доверять AI-агентам, а какие нет?

Автор — Антипов Дмитрий
Руководитель разработки AI-продуктов в СБЕР (АБТ)

Практическая статья про AI-агенты: рассказываем, где их применять и какие ошибки избегать при их проектировании
AI-агенты сегодня стали одним из самых обсуждаемых направлений в области искусственного интеллекта. Их активно используют в продуктах, стартапах и корпоративных системах, часто называя «решением для всего». Однако вместе с популярностью растёт и путаница: под агентами нередко понимают любые системы, где используется языковая модель, хотя это далеко не всегда корректно
В этой статье разберём, что на самом деле является AI-агентом, какие подходы к нему не относятся, в каких задачах агенты действительно полезны, а также какие ошибки и антипаттерны чаще всего встречаются при их разработке.
В этой статье разберём, что на самом деле является AI-агентом, какие подходы к нему не относятся, в каких задачах агенты действительно полезны, а также какие ошибки и антипаттерны чаще всего встречаются при их разработке.

1. Что не является AI-агентом?
Сначала разберёмся с распространенным заблуждением — что на самом деле не является AI-агентом.
Сегодня этот термин используют очень широко, зачастую называя так практически любую систему с языковой моделью. Однако ни простой вызов модели, ни усложненный запрос, ни цепочки вызовов, ни роутинг между ними сами по себе AI-агентами не являются. Это всё лишь способы использования языковой модели внутри программного обеспечения.
Сегодня этот термин используют очень широко, зачастую называя так практически любую систему с языковой моделью. Однако ни простой вызов модели, ни усложненный запрос, ни цепочки вызовов, ни роутинг между ними сами по себе AI-агентами не являются. Это всё лишь способы использования языковой модели внутри программного обеспечения.
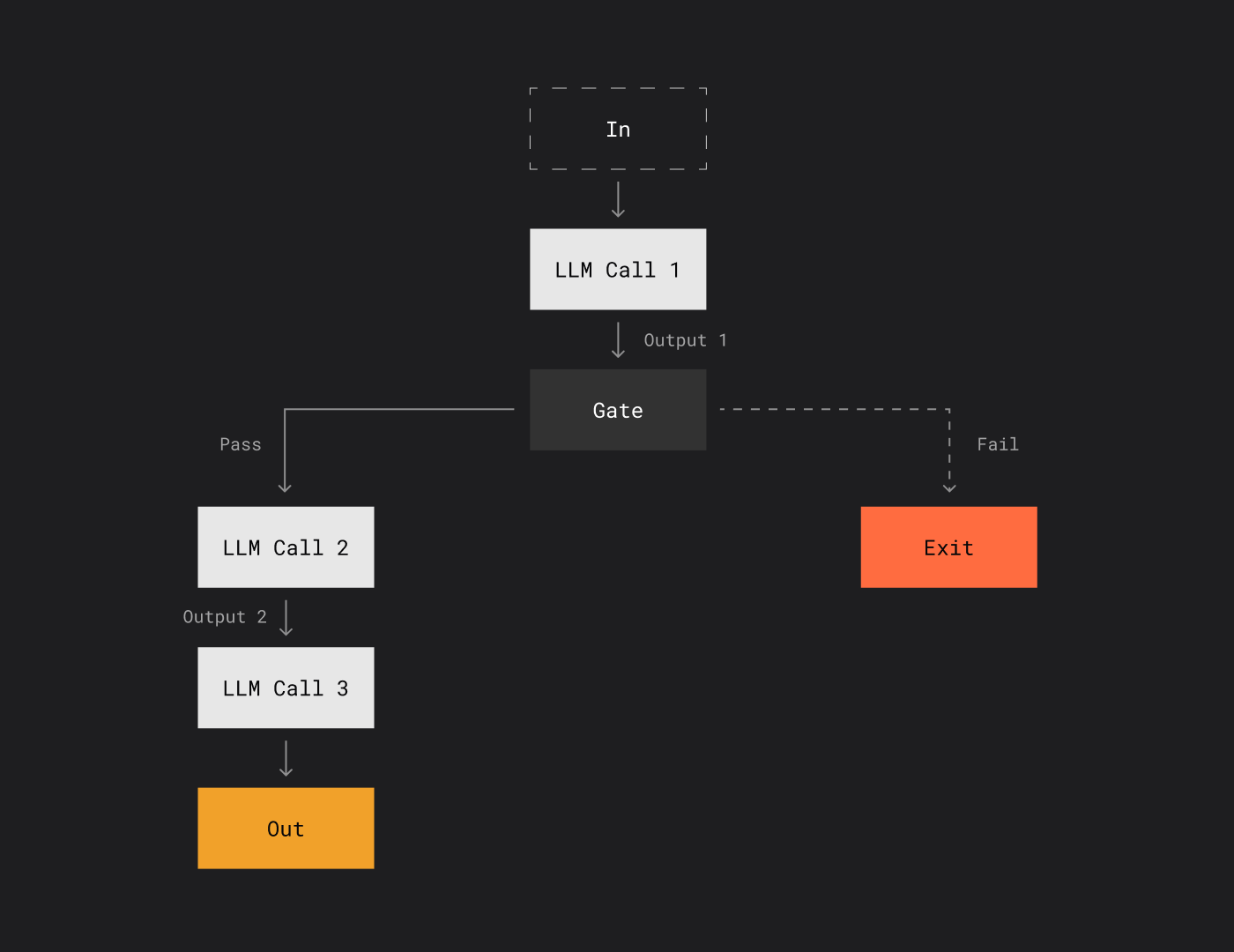
Даже такие подходы, как распараллеливание запросов или базовая оркестрация, где одна модель передает результат другой, всё ещё не делают систему агентом.
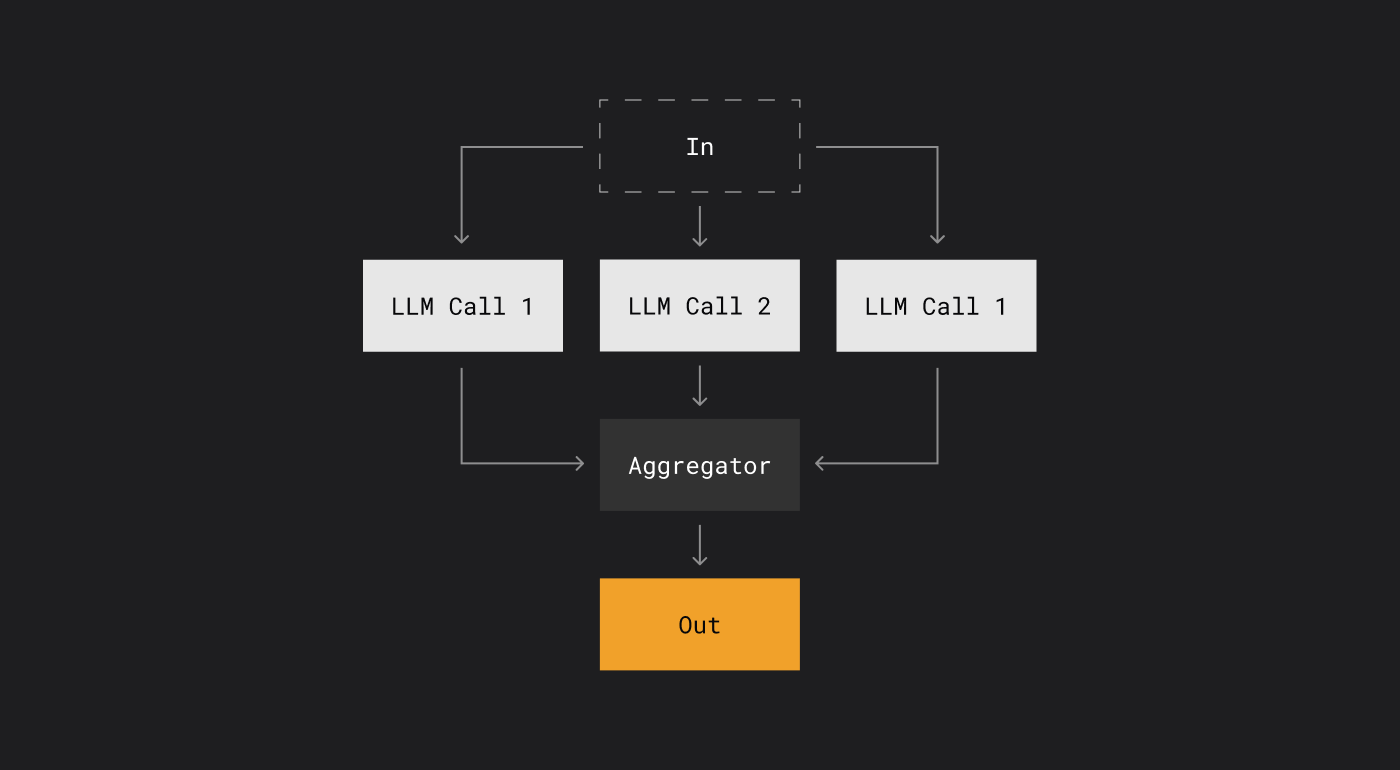
Как бы сложно ни выглядела комбинация этих техник, сама по себе она не превращает систему в AI-агента — у него есть дополнительные характеристики, которые выходят за рамки таких паттернов.
2. Что такое AI-агент?
Если попробовать интуитивно объяснить, что это такое, можно вспомнить знакомые с детства примеры. Например, Вовка в тридевятом царстве — это наглядная иллюстрация агентного поведения.
Правда, скорее это пример антипаттерна, но к этому мы ещё вернёмся и отдельно обсудим.
Правда, скорее это пример антипаттерна, но к этому мы ещё вернёмся и отдельно обсудим.
Если же дать простое и практичное определение, то AI-агент — это система, в которой хотя бы часть шагов выполняется самостоятельно, без явного пошагового управления извне.
3. Подходящие задачи для AI-агентов
Теперь давайте разберёмся, какие задачи имеет смысл поручать агентам. Сначала перечислим основные категории, а затем подробнее рассмотрим каждую из них с точки зрения плюсов и ограничений.
К таким задачам относятся:
- работа с кодом
- ресерч и эксперименты
- аналитика
- слабо структурированные повторяющиеся задачи
- создание продуктов
- ответы на вопросы с использованием разных источников
- генерация данных
Зафиксируем этот список и последовательно пройдемся по каждому пункту.
Работа с кодом
Сегодня уже ни для кого не секрет — языковые модели и агенты, построенные на их основе, умеют писать качественный код.
При этом их возможности не ограничиваются только генерацией: они могут проверять код, анализировать решения, валидировать тестовые задания и в целом работать с кодом на разных этапах его жизненного цикла.
Одно из ключевых преимуществ здесь — хорошая тестируемость результата. Мы можем написать тест, и он либо проходит, либо нет. Это позволяет выстроить почти идеальный цикл итераций: система генерирует решение, проверяет его, исправляет ошибки и повторяет этот процесс до тех пор, пока тесты не начнут проходить.
Однако есть и ограничения. Такая система не видит всей архитектуры целиком. В результате она может фокусироваться не на качестве решения, а на прохождении тестов — так называемый «test hacking». То есть вместо того, чтобы корректно решить задачу, система подстраивается под тесты. В отдельных случаях это может приводить к деградации архитектуры.
При этом их возможности не ограничиваются только генерацией: они могут проверять код, анализировать решения, валидировать тестовые задания и в целом работать с кодом на разных этапах его жизненного цикла.
Одно из ключевых преимуществ здесь — хорошая тестируемость результата. Мы можем написать тест, и он либо проходит, либо нет. Это позволяет выстроить почти идеальный цикл итераций: система генерирует решение, проверяет его, исправляет ошибки и повторяет этот процесс до тех пор, пока тесты не начнут проходить.
Однако есть и ограничения. Такая система не видит всей архитектуры целиком. В результате она может фокусироваться не на качестве решения, а на прохождении тестов — так называемый «test hacking». То есть вместо того, чтобы корректно решить задачу, система подстраивается под тесты. В отдельных случаях это может приводить к деградации архитектуры.
Плюсы:
- тестируемость результата
- идеальный цикл исправления
Минусы:
- не видит всю систему
- test hacking и поломка архитектуры
Research, исследования и эксперименты
Основное преимущество — агент может одновременно работать с большим количеством инструментов и источников, а также обрабатывать задачи в свободной форме. Например: «подготовь отчёт» или «помоги выбрать решение». Система способна собрать данные из множества источников и быстро их обработать.
Сюда же относятся и эксперименты, особенно в ML-практике. По сути, эксперимент — это итеративный процесс: мы запускаем модель с определёнными параметрами, анализируем результат, фиксируем его, затем корректируем параметры и повторяем цикл снова и снова. Несмотря на сложность такого процесса, он хорошо подходит для агентов, так как перебор параметров и повторяющиеся итерации — это как раз их сильная сторона.
Однако есть и важные ограничения. Главная проблема — это качество источников. При работе с большим количеством данных часто отсутствует слой валидации: система получает информацию и по умолчанию считает её корректной, хотя это может быть не так.
Кроме того, такие системы могут быть чрезмерно автономными — порой без участия человека они не способны вовремя остановиться. Поэтому человеческий контроль в таких задачах остаётся необходимым.
Сюда же относятся и эксперименты, особенно в ML-практике. По сути, эксперимент — это итеративный процесс: мы запускаем модель с определёнными параметрами, анализируем результат, фиксируем его, затем корректируем параметры и повторяем цикл снова и снова. Несмотря на сложность такого процесса, он хорошо подходит для агентов, так как перебор параметров и повторяющиеся итерации — это как раз их сильная сторона.
Однако есть и важные ограничения. Главная проблема — это качество источников. При работе с большим количеством данных часто отсутствует слой валидации: система получает информацию и по умолчанию считает её корректной, хотя это может быть не так.
Кроме того, такие системы могут быть чрезмерно автономными — порой без участия человека они не способны вовремя остановиться. Поэтому человеческий контроль в таких задачах остаётся необходимым.
Плюсы:
- быстрая обработка множества источников
- любая задача в свободной форме
- автоизменение параметров для экспериментов
Минусы:
- проблема источников
- без человека не знает, когда остановиться
Аналитика и расследование аномалий
Главное преимущество — при возникновении проблемы система может генерировать большое количество гипотез и последовательно их проверять. При этом отсутствует предвзятость: агент способен гибко менять направление анализа, углубляться в разные аспекты и адаптировать параметры исследования по ходу работы.
Однако есть и существенные ограничения. Языковые модели очень мощные, поэтому иногда они начинают находить закономерности там, где их на самом деле нет. Это может приводить к ложным выводам.
Кроме того, для запуска таких систем часто требуется значительное количество доступов, инфраструктуры и интеграций. На практике это становится серьезным барьером и усложняет внедрение подобных решений.
Однако есть и существенные ограничения. Языковые модели очень мощные, поэтому иногда они начинают находить закономерности там, где их на самом деле нет. Это может приводить к ложным выводам.
Кроме того, для запуска таких систем часто требуется значительное количество доступов, инфраструктуры и интеграций. На практике это становится серьезным барьером и усложняет внедрение подобных решений.
Плюсы:
- генератор гипотез и их проверка
- отсутствует предвзятость
- автоизменение параметров для экспериментов
Минусы:
- находит то, чего нет
- нужна инфраструктура и доступы
Слабоструктурированные повторяющиеся задачи / Маршрутизация
К этой категории относятся задачи с большим разнообразием сценариев: например, ипотека, потерянная карта или новый финансовый продукт.
Общая сложность: для таких кейсов часто нет чётких и жёстких правил обработки. И именно в таких условиях языковые модели и агенты показывают себя лучше всего — они способны гибко адаптироваться под разные типы запросов.
Дополнительное преимущество — это масштабируемость. Такие системы легко масштабируются горизонтально: можно запустить десятки, сотни или даже тысячи инстансов. Это принципиально отличается от работы с людьми, где масштабирование всегда ограничено.
Однако есть и недостатки. В подобных системах часто возникают неочевидные ошибки, например, запрос может быть отправлен не в тот сценарий, и это может остаться незамеченным.
Кроме того, иногда система не справляется с точной маршрутизацией — ей не всегда удается корректно определить, куда именно нужно направить конкретный запрос, и такие ошибки легко пропустить.
Общая сложность: для таких кейсов часто нет чётких и жёстких правил обработки. И именно в таких условиях языковые модели и агенты показывают себя лучше всего — они способны гибко адаптироваться под разные типы запросов.
Дополнительное преимущество — это масштабируемость. Такие системы легко масштабируются горизонтально: можно запустить десятки, сотни или даже тысячи инстансов. Это принципиально отличается от работы с людьми, где масштабирование всегда ограничено.
Однако есть и недостатки. В подобных системах часто возникают неочевидные ошибки, например, запрос может быть отправлен не в тот сценарий, и это может остаться незамеченным.
Кроме того, иногда система не справляется с точной маршрутизацией — ей не всегда удается корректно определить, куда именно нужно направить конкретный запрос, и такие ошибки легко пропустить.
Плюсы:
- обработка без жестоких правил
- сверхмасштабирование
Минусы:
- неуловимые ошибки
- сложность граничных ситуаций
Создание продуктов и прототипирование
Многие уже пробовали собирать MVP и proof of concept на основе языковых моделей и агентов.
Ключевое преимущество здесь — высокая скорость. Такие решения позволяют быстро собирать прототипы и проверять разные гипотезы. Можно делать несколько версий продукта и оперативно сравнивать их между собой.
Кроме того, это удобный инструмент для синхронизации ожиданий. Когда у команды разное представление о том, как должен выглядеть продукт, вместо обсуждений и макетов можно быстро собрать рабочий интерфейс и зафиксировать: «да, вот это оно», и двигаться дальше.
Однако есть и существенные минусы. Во-первых, такие прототипы часто создают завышенные ожидания — может показаться, что продукт уже почти готов, и непонятно, зачем требуется дополнительное время на разработку.
Во-вторых, есть риски для архитектуры. Подобные решения могут незаметно ломать систему: например, при добавлении небольшой функции агент может удалить важные части кода, такие как подключение к базе данных. И такие изменения не всегда сразу заметны, что делает проблему особенно критичной.
Ключевое преимущество здесь — высокая скорость. Такие решения позволяют быстро собирать прототипы и проверять разные гипотезы. Можно делать несколько версий продукта и оперативно сравнивать их между собой.
Кроме того, это удобный инструмент для синхронизации ожиданий. Когда у команды разное представление о том, как должен выглядеть продукт, вместо обсуждений и макетов можно быстро собрать рабочий интерфейс и зафиксировать: «да, вот это оно», и двигаться дальше.
Однако есть и существенные минусы. Во-первых, такие прототипы часто создают завышенные ожидания — может показаться, что продукт уже почти готов, и непонятно, зачем требуется дополнительное время на разработку.
Во-вторых, есть риски для архитектуры. Подобные решения могут незаметно ломать систему: например, при добавлении небольшой функции агент может удалить важные части кода, такие как подключение к базе данных. И такие изменения не всегда сразу заметны, что делает проблему особенно критичной.
Плюсы:
- супер-быстрые MVP и PoC
- сборка разных версий
Минусы:
- повышение ожиданий, ведь «уже всё готово»
- проблема архитектуры
Ответы из разных источников, или multi-source Q&A
Когда у нас есть большое количество источников, в которые нам нужно сходить, чтобы забрать, очень часто бывает проблема того, что они написаны на разных языках.
Допустим, ГОС написан на одном языке, какое-то письмо о том, как мы работаем с клиентами, написано на другом. И вот это все собрать, сконцентрировать в себе, и чтобы из этого собрать единый ToV-ответ, который соответствует компании — вот здесь такая система очень хорошо подходит.
Минусы — эта система уверена даже когда она ошибается. То есть вот она сделала ошибку, но все равно говорит тебе — ничего страшного, все же правильно.
Нам очень важно поймать тот момент, когда система может делать ошибки.
И такая система плоха тем, что здесь происходит быстрое устаревание данных. Если кто-то забыл обновить источник, все, что мы строим, может работать плохо.
Допустим, ГОС написан на одном языке, какое-то письмо о том, как мы работаем с клиентами, написано на другом. И вот это все собрать, сконцентрировать в себе, и чтобы из этого собрать единый ToV-ответ, который соответствует компании — вот здесь такая система очень хорошо подходит.
Минусы — эта система уверена даже когда она ошибается. То есть вот она сделала ошибку, но все равно говорит тебе — ничего страшного, все же правильно.
Нам очень важно поймать тот момент, когда система может делать ошибки.
И такая система плоха тем, что здесь происходит быстрое устаревание данных. Если кто-то забыл обновить источник, все, что мы строим, может работать плохо.
Плюсы:
- собирает ответ из множества источников
- улучшение качества ответа
Минусы:
- уверенность даже в ошибках
- быстрое устаревание данных
Генерация данных
Ключевая особенность этой категории — практически неограниченные возможности генерации. Система может создавать любые типы данных: тексты, структуры, базы данных, изображения и многое другое.
Однако такая гибкость требует опыта. Чтобы получать качественный результат, важно правильно настраивать процесс генерации и понимать его ограничения.
Кроме того, на ключевых этапах необходима валидация со стороны человека — без этого сложно гарантировать корректность и пригодность сгенерированных данных.
Однако такая гибкость требует опыта. Чтобы получать качественный результат, важно правильно настраивать процесс генерации и понимать его ограничения.
Кроме того, на ключевых этапах необходима валидация со стороны человека — без этого сложно гарантировать корректность и пригодность сгенерированных данных.
Плюсы:
- можно сделать всё, что угодно
Минусы:
- требуется валидация человеком на ключевых этапах
4. Антипаттерны
Мы разобрали, какие задачи подходят для агентов, а теперь посмотрим на распространённые ошибки при их использовании.
God Agent (решатель всего)
Один из самых частых антипаттернов — попытка сделать «универсального агента», который решает любые задачи.
Основная идея — система «сама во всём разберётся». На практике это не работает: без четкой области ответственности и ограничений такие решения становятся неуправляемыми и быстро теряют качество.
Основная идея — система «сама во всём разберётся». На практике это не работает: без четкой области ответственности и ограничений такие решения становятся неуправляемыми и быстро теряют качество.
Оверинжиниринг (для детерминированных задач)
Ещё одна ошибка — усложнение там, где это не нужно. Если задача простая и хорошо формализована, нет смысла строить сложную систему из нескольких агентов. Часто уже существует надежное и простое решение, которое справляется с задачей лучше и стабильнее.
Демо без бенчмаркинга / evals
Очень часто MVP и прототипы выглядят убедительно на демо, но начинают рассыпаться, как только сталкиваются с реальной жизнью и реальными сценариями использования.
Поэтому любое MVP, которое мы делаем, важно сразу обвешивать хотя бы минимальным набором бенчмаркингов и eval-систем. Речь идет о механизмах, которые позволяют контролировать всё, что входит в систему и выходит из неё, строить метрики качества и регулярно калибровать поведение модели.
Такие инструменты дают возможность не просто «посмотреть демо», а реально понять, насколько система работает стабильно и корректно в разных условиях. Без этого контроль качества становится невозможным: мы не видим деградаций, не понимаем, где система ошибается, и не можем системно улучшать решение.
Поэтому любое MVP, которое мы делаем, важно сразу обвешивать хотя бы минимальным набором бенчмаркингов и eval-систем. Речь идет о механизмах, которые позволяют контролировать всё, что входит в систему и выходит из неё, строить метрики качества и регулярно калибровать поведение модели.
Такие инструменты дают возможность не просто «посмотреть демо», а реально понять, насколько система работает стабильно и корректно в разных условиях. Без этого контроль качества становится невозможным: мы не видим деградаций, не понимаем, где система ошибается, и не можем системно улучшать решение.
Промптинг вместо пересмотра архитектуры
Часто возникает иллюзия: любую проблему можно решить «магическим промптом».
Если один промпт не работает, пытаются просто переписать запрос — вместо того чтобы пересмотреть архитектуру.
На практике многие задачи не решаются на уровне промптинга. Они требуют изменений в дизайне системы и продуманной архитектуры.
Если один промпт не работает, пытаются просто переписать запрос — вместо того чтобы пересмотреть архитектуру.
На практике многие задачи не решаются на уровне промптинга. Они требуют изменений в дизайне системы и продуманной архитектуры.
Отсутствие наблюдаемости
Агентные системы — это сложные и не всегда предсказуемые механизмы. Если за ними не следить, они могут вести себя неожиданно. Поэтому важно обеспечивать наблюдаемость: понимать, какие процессы происходят внутри системы, сколько ресурсов она потребляет, как проходят циклы выполнения и какие условия выхода используются.
Сразу в прод без HITL (human-in-the-loop)
Ещё одна ошибка — запуск решения в прод без предварительной валидации.
Помимо стандартных метрик, важно учитывать и специфику агентных систем — в том числе необходимость участия человека. Контроль со стороны человека позволяет вовремя замечать ошибки и корректировать поведение системы.
Даже если система работает на демо, это не означает, что она готова к реальной нагрузке. Подход «human-in-the-loop» предполагает, что после запуска человек регулярно проверяет результаты и оценивает корректность работы системы.
Помимо стандартных метрик, важно учитывать и специфику агентных систем — в том числе необходимость участия человека. Контроль со стороны человека позволяет вовремя замечать ошибки и корректировать поведение системы.
Даже если система работает на демо, это не означает, что она готова к реальной нагрузке. Подход «human-in-the-loop» предполагает, что после запуска человек регулярно проверяет результаты и оценивает корректность работы системы.
Выделяя несколько ключевых антипаттернов, стоит помнить — на практике способов «сломать» систему гораздо больше
Например, избыточное количество инструментов или попытка решить проблему за счёт увеличения числа агентов вместо проработки архитектуры.
Главная ошибка — ожидание, что агент «сам разберётся». Без продуманной архитектуры, четкого целеполагания и контроля такие системы не работают надёжно.
Главная ошибка — ожидание, что агент «сам разберётся». Без продуманной архитектуры, четкого целеполагания и контроля такие системы не работают надёжно.
5. Инженерная интуиция
Чтобы лучше понять, что такое агент, можно сделать простое мысленное упражнение: заменить слово «агент» на «микросервис». В таком представлении с агентами становится гораздо проще работать.
Агент — это действительно некий микросервис: у него есть вход, есть выход, и он выполняет определённую функцию внутри системы.
Агент — это действительно некий микросервис: у него есть вход, есть выход, и он выполняет определённую функцию внутри системы.
Но важно учитывать ключевое отличие — это крайне нестабильный микросервис. Он может вести себя непредсказуемо, «падать», менять формат ответов и в целом работать не так детерминированно, как привычные сервисы.
Если воспринимать агента как полноценную часть архитектуры — такую же, как и любой другой микросервис, — становится понятнее, как с ним работать: его нужно правильно встраивать, окружать инфраструктурой и учитывать его ограничения.
По сути, это самый нестабильный и наименее предсказуемый микросервис в системе.
По сути, это самый нестабильный и наименее предсказуемый микросервис в системе.
6. Проектирование AI-агентов
Работа с агентами всегда начинается с проектирования. Первый шаг — это понять, что именно мы хотим построить. Нужно задизайнить систему на верхнем уровне и определить, где в ней действительно нужен агент.
Когда есть общее архитектурное представление, становится понятно, в каком месте агент уместен и какую именно логику он должен реализовывать — не просто вызовы модели, а именно агентную, более сложную логику.
Когда есть общее архитектурное представление, становится понятно, в каком месте агент уместен и какую именно логику он должен реализовывать — не просто вызовы модели, а именно агентную, более сложную логику.
При этом вокруг агента должен быть выстроен полноценный системный дизайн — такой же, как и для любого другого микросервиса. Архитектура здесь критически важна.
Подход «давайте быстро сделаем агента, который всё решит» на практике не работает. Без продуманной архитектуры такие решения оказываются нестабильными и плохо управляемыми.
7. Заключение
AI-агенты — это не любая система с языковой моделью. Ни одиночные вызовы, ни цепочки, ни роутинг или оркестрация сами по себе не делают систему агентом. Агент появляется там, где часть шагов выполняется самостоятельно, без жесткого пошагового управления.
Лучше всего агенты работают в задачах с высокой неопределённостью: анализ, эксперименты, работа с множеством источников, слабоструктурированные процессы, генерация и прототипирование. Их сильные стороны — гибкость, масштабируемость и способность работать без строгих правил.
Но у этого есть цена: ошибки в источниках, излишняя «уверенность» в неверных ответах, сложность контроля, неочевидные сбои и необходимость человеческого участия. Без human-in-the-loop такие системы быстро теряют стабильность.
Важно избегать антипаттернов, например, попыток сделать «универсального агента», усложнения простых задач, отсутствия метрик и бенчмаркинга, использование промптинга вместо архитектуры, отсутствия наблюдаемости и запуска в прод без проверки.
Лучше всего агенты работают в задачах с высокой неопределённостью: анализ, эксперименты, работа с множеством источников, слабоструктурированные процессы, генерация и прототипирование. Их сильные стороны — гибкость, масштабируемость и способность работать без строгих правил.
Но у этого есть цена: ошибки в источниках, излишняя «уверенность» в неверных ответах, сложность контроля, неочевидные сбои и необходимость человеческого участия. Без human-in-the-loop такие системы быстро теряют стабильность.
Важно избегать антипаттернов, например, попыток сделать «универсального агента», усложнения простых задач, отсутствия метрик и бенчмаркинга, использование промптинга вместо архитектуры, отсутствия наблюдаемости и запуска в прод без проверки.
В инженерном смысле AI-агент — это нестабильный микросервис, который требует полноценной архитектуры, контроля качества и четких границ ответственности. Только в этом случае ИИ-агент становится рабочим инструментом, а не источником хаоса.
Другие статьи
АИ-агент — это программная система, которая способна самостоятельно выполнять разные задачи. С агентом можно анализировать данные, принимать решения, взаимодействовать с API, вызывать инструменты и управлять бизнес-процессами.
В отличие от обычных чат-ботов, AI-ассистенты работают не по жесткому сценарию, а адаптируются к контексту и могут выполнять последовательность действий без постоянного участия человека. Такие агенты работают, используя алгоритм машинного обучения, способны обучаться на основе предыдущих действий и анализируют информацию для получения более точного результата.
Для программистов освоение ИИ становятся важной частью современной backend- и enterprise-разработки. АИ-агентов можно использовать для автоматизации внутренних сервисов бизнеса, обработки событий, orchestration-процессов и построения intelligent workflow внутри распределенных систем. Особенно активно АИ-агенты внедряются в event-driven архитектуру, микросервисы и highload-платформы. Сегодня многие компании стремятся внедрить ИИ в корпоративные приложения, используя доступные инструменты и API для реализации сложных сценариев.
В разработке АИ-агентов можно использовать для автоматизации DevOps-задач, генерации документации, анализа логов, мониторинга инфраструктуры и обработки инцидентов. Агенты самостоятельно выполняют задачи: они могут обнаружить ошибку, собрать диагностическую информацию, создать задачу в трекере или запустить recovery-сценарий. Такой подход снижает нагрузку на инженерные команды и ускоряет реакцию на проблемы. Кроме того, AI-ассистент способен автоматически выполнять рутинные операции, предлагать инструкции для сотрудников и помогать в оптимизации рабочих процессов.
Отдельное направление — АИ-агенты для работы с данными и бизнес-логикой. Они помогают строить интеллектуальные пайплайны, анализировать пользовательские действия, координировать сервисы через Kafka, интегрироваться с LLM-моделями и управлять потоками данных в реальном времени. Для backend-разработчиков это открывает возможность создавать self-managed системы с более высоким уровнем автоматизации. Подобное применение AI особенно востребовано в сервисах поддержки, продажах и на цифровых платформах, где важны скорость обработки запросов и эффективность взаимодействия с клиентами.
Современные AI-ассистенты часто работают как часть distributed architecture: используют очереди сообщений, vector database, memory layer, external tools и orchestration-frameworks. Поэтому разработчику важно понимать не только основы machine learning, но и архитектуру AI-систем, работу inference-процессов, latency, observability и scaling distributed workloads. Дополнительно требуется настройка интеграции с внешними сервисами, контроль зависимости между компонентами и безопасность обработки данных в интернете. Во многих проектах AI-ассистенты создаются с помощью Python и специализированных framework-решений для максимально быстрой разработки.
AI-ассистенты уже становятся стандартным инструментом для бизнеса. Их внедряют в fintech, SaaS, e-commerce, cloud platforms и enterprise-системы, где требуется автоматизация сложных процессов, высокая скорость обработки данных и интеллектуальное взаимодействие между сервисами. Агенты позволяют автоматизировать коммуникацию, отвечать на запросы пользователей, общаться с клиентами на естественного языке и выполнять различные бизнес-стратегии без постоянного участия человека.
Для компаний агенты - это не только экономия ресурсов, но и будущее корпоративного ПО, где виртуальный AI-помощник самостоятельно выбирает оптимальные действия по заданным правилам. Производительность подобных систем растет благодаря развитию LLM-моделей, а современные AI-агенты способны выполнить сложные задачи практически без участия разработчиков.
Мы подготовили курс, где научим тебя с нуля создавать и использовать в своих в процессах сложных агентов для задач бизнеса.
Курс по ИИ-агентам длится 1 месяц в удобном онлайн-формате. В процессе обучения будем тренироваться на агентах и писать их самостоятельно либо ты можешь создать своего агента - по своей идее или реальному рабочему проекту. В конце выдаем сертификат об освоении агентов.
Преподавать на курсе по AI-агентам будет Дмитрий Антипов, руководитель разработки AI-продуктов в Группе Сбер (АБТ). Сейчас он занимается разработкой и внедрением агентов в юр-отдел, бухгалтерию, колл-центры, аналитику. У Дмитрия уже 7 лет опыта в AI-инженерии - и он поделится своим опытом и знаниями по агентам на нашем курсе.
В отличие от обычных чат-ботов, AI-ассистенты работают не по жесткому сценарию, а адаптируются к контексту и могут выполнять последовательность действий без постоянного участия человека. Такие агенты работают, используя алгоритм машинного обучения, способны обучаться на основе предыдущих действий и анализируют информацию для получения более точного результата.
Для программистов освоение ИИ становятся важной частью современной backend- и enterprise-разработки. АИ-агентов можно использовать для автоматизации внутренних сервисов бизнеса, обработки событий, orchestration-процессов и построения intelligent workflow внутри распределенных систем. Особенно активно АИ-агенты внедряются в event-driven архитектуру, микросервисы и highload-платформы. Сегодня многие компании стремятся внедрить ИИ в корпоративные приложения, используя доступные инструменты и API для реализации сложных сценариев.
В разработке АИ-агентов можно использовать для автоматизации DevOps-задач, генерации документации, анализа логов, мониторинга инфраструктуры и обработки инцидентов. Агенты самостоятельно выполняют задачи: они могут обнаружить ошибку, собрать диагностическую информацию, создать задачу в трекере или запустить recovery-сценарий. Такой подход снижает нагрузку на инженерные команды и ускоряет реакцию на проблемы. Кроме того, AI-ассистент способен автоматически выполнять рутинные операции, предлагать инструкции для сотрудников и помогать в оптимизации рабочих процессов.
Отдельное направление — АИ-агенты для работы с данными и бизнес-логикой. Они помогают строить интеллектуальные пайплайны, анализировать пользовательские действия, координировать сервисы через Kafka, интегрироваться с LLM-моделями и управлять потоками данных в реальном времени. Для backend-разработчиков это открывает возможность создавать self-managed системы с более высоким уровнем автоматизации. Подобное применение AI особенно востребовано в сервисах поддержки, продажах и на цифровых платформах, где важны скорость обработки запросов и эффективность взаимодействия с клиентами.
Современные AI-ассистенты часто работают как часть distributed architecture: используют очереди сообщений, vector database, memory layer, external tools и orchestration-frameworks. Поэтому разработчику важно понимать не только основы machine learning, но и архитектуру AI-систем, работу inference-процессов, latency, observability и scaling distributed workloads. Дополнительно требуется настройка интеграции с внешними сервисами, контроль зависимости между компонентами и безопасность обработки данных в интернете. Во многих проектах AI-ассистенты создаются с помощью Python и специализированных framework-решений для максимально быстрой разработки.
AI-ассистенты уже становятся стандартным инструментом для бизнеса. Их внедряют в fintech, SaaS, e-commerce, cloud platforms и enterprise-системы, где требуется автоматизация сложных процессов, высокая скорость обработки данных и интеллектуальное взаимодействие между сервисами. Агенты позволяют автоматизировать коммуникацию, отвечать на запросы пользователей, общаться с клиентами на естественного языке и выполнять различные бизнес-стратегии без постоянного участия человека.
Для компаний агенты - это не только экономия ресурсов, но и будущее корпоративного ПО, где виртуальный AI-помощник самостоятельно выбирает оптимальные действия по заданным правилам. Производительность подобных систем растет благодаря развитию LLM-моделей, а современные AI-агенты способны выполнить сложные задачи практически без участия разработчиков.
Мы подготовили курс, где научим тебя с нуля создавать и использовать в своих в процессах сложных агентов для задач бизнеса.
Курс по ИИ-агентам длится 1 месяц в удобном онлайн-формате. В процессе обучения будем тренироваться на агентах и писать их самостоятельно либо ты можешь создать своего агента - по своей идее или реальному рабочему проекту. В конце выдаем сертификат об освоении агентов.
Преподавать на курсе по AI-агентам будет Дмитрий Антипов, руководитель разработки AI-продуктов в Группе Сбер (АБТ). Сейчас он занимается разработкой и внедрением агентов в юр-отдел, бухгалтерию, колл-центры, аналитику. У Дмитрия уже 7 лет опыта в AI-инженерии - и он поделится своим опытом и знаниями по агентам на нашем курсе.